Praktisch alle mittleren und großen Unternehmen haben sich inzwischen eine Cloud-Strategie verschrieben. Für die IT-Abteilung stellt sich nun die Frage, wie sie in Zukunft das Cloud Management betreiben sollen.
Fahrplan für diesen Blog-Beitrag
Um dem Thema gerecht zu werden, bedarf es einer Betrachtung aus verschiedenen Perspektiven und bestimmter Vorklärungen. Deshalb ist der Artikel in folgende größere Abschnitte unterteilt.
Teil 1 des Artikels beschäftigt sich mit den Themen:
- Cloud Computing und wo geht die Strategie der Unternehmen hin
- State-of-the-Art-Anwendungsarchitekturen für die Cloud
- Herausforderungen an Systems und Service Management in der Cloud
Teil 2 mit den Themen:
- Beispiele für die technische Umsetzung
- Fazit und Empfehlung
Was ist Cloud?
Die Cloud-Strategien der Unternehmen sind vielfältig und der Begriff „Cloud“ ist vieldeutig besetzt, auch deshalb weil IT-Provider, also Anbieter von IT-Verarbeitungsleistungen, gerne alles was sie anbieten mit dem inzwischen durchaus positiven besetzten Begriff Cloud vermarkten. Gerne werden die NIST Definition of Cloud Computing aus dem Jahr 2011 zur Erklärung herangezogen, die einen gewissen Standarddefinitions-Charakter haben, aber man muss konzedieren, dass sich die Cloud-Welt seit 2011 auch wesentlich weiterentwickelt hat. Im Jahr 2018 hat sich bei den führenden Public Cloud-Anbietern, wie Amazon Web Service (AWS), Microsoft Azure, IBM Cloud, Google Cloud Computing und anderen, ein gemeinsames Verständnis herausgebildet, dass (Public) Cloud Computing im Wesentlichen die Bereitstellung von umfassenden Service-Baukästen bedeutet, aus denen sich teilweise in riesige Dimensionen skalierbare Unternehmensanwendungen in Minuten zusammenstellen lassen. Der gute alte Server in der Public Cloud (IaaS) ist fast ein Relikt geworden und steht sicher nicht mehr im Zentrum einer Cloud-Strategie. Wie hat es ein IT-Manager eines Konzerns uns gegenüber vor Kurzem trefflich auf den Punkt gebracht: „Das Thema Private Cloud hat sich praktisch erledigt. Die großen Anbieter sind uns in punkto Serviceangebot derart voraus, das werden wir nie mehr aufholen können.“ Deshalb bieten Firmen wie Microsoft und IBM, die sowohl Cloud-Provider als auch Softwarehersteller sind, ihren Kunden Cloud-Technologien zum Aufbau einer Private Cloud an, die die gleichen Funktionen bieten, wie ihre Public Clouds.
Public Clouds sind vollkommen software-definierte Umgebungen, die Konfiguration erfolgt ausschließlich über APIs bzw. Kommandos. Zugang zur Cloud Fabric zwecks Management, also den internen Hardware-Ressourcen und Software-Diensten, ist in der Regel nicht gegeben und auch nicht erwünscht.
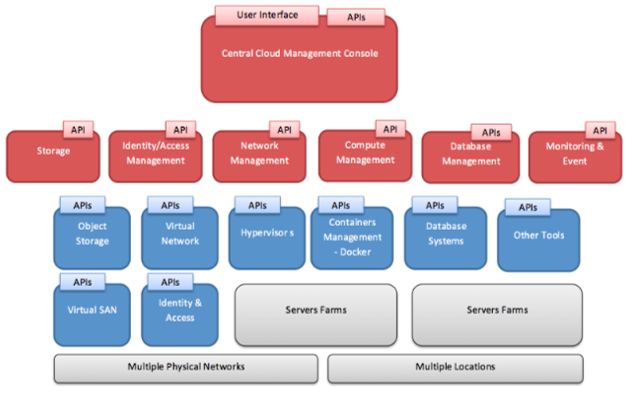
Unternehmensanwendungen in der Public Cloud
Damit ist im Wesentlichen vorgegeben, was zukünftig in die Public Cloud geht. Es sind die sog. „Systems of Engagement“, also die Unternehmensanwendungen, die Schnittstellen zu Kunden, Partner oder den eigenen Produkten, die im Rahmen der Digitalisierung wichtig werden – meist auch geographisch weit verteilt und mit hohen Verfügbarkeitsanforderungen ausgestattet – darstellen. Die „Systems of Record“, also die Kernunternehmensanwendungen verbleiben im eigenen Rechenzentrum oder werden in Gänze zu einen Outsourcer verlagert (was aber kein Cloud Computing ist). Der IT-Leiter einer großen deutschen Versicherung hat uns gegenüber auch die in seinem Haus definierte Kategorie der „Systems of Innovation“ erwähnt, die nur in die Public Cloud gehen, sprich den neuen Unternehmensanwendungen, die neue Geschäftsmodelle unterstützen. Und dann sind da noch die nicht-geschäftskritischen IT-Anwendungen, die „Systems of Commodity“, die gerne als komplettes Leistungspaket in der Cloud (SaaS) angemietet werden, wie z.B. Office365 für alles was auf den Endgeräten läuft bzw. an Kollaborationsanwendungen benötigt wird oder CRM-Systeme wie Salesforce, weil sie hochgradig standardisiert sind.
Damit spielt die Public Cloud auch eine Rolle in der Umsetzung einer bimodalen IT, wobei bimodal eher ein organisatorisches und prozessuales Konzept als ein technisches ist, aber die Agilität der Public Cloud hilfreich ist. Das Konzept der hybriden Cloud, wo on-premise Anwendungen bei Bedarf auch in die Public Cloud skalieren sollen, ist zunehmend überholt, insbesondere weil die früheren Bedenken bzgl. Datenschutz und Informationssicherheit in der Public Cloud immer weniger greifen und wenn dann ganz oder gar nicht in die Cloud ausgelagert wird.
Anwendungsarchitekturen in der Cloud
Das bedeutet nun, dass in Zukunft vorwiegend Anwendungen mit neuartiger Architektur in der Public Cloud betrieben werden, außer vielleicht einzelne virtuelle Entwicklung- und Testsysteme, weil die unkritisch und in der Cloud preisgünstig zu mieten sind. Die Grundprinzipien wie moderne Anwendungsarchitekturen auszusehen haben, um Cloud-Umgebungen optimal zu nutzen, liefert das 12-Faktor-Manifest. Hält man sich bei der Anwendungsarchitektur an das 12-Faktor-Manifest, dann entsteht mehr oder minder zwangsläufig eine sog. Microservice-Architektur, wie die folgende Abbildung verdeutlicht:
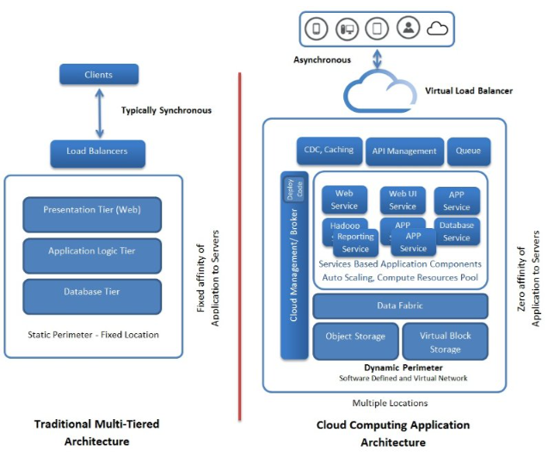
Das technische Mittel, mit denen solche Microservice-Architekturen heutzutage umgesetzt werden, sind sog. Container und Container Orchestration-Systeme. Container sind ausführbare Programmdateien, die den Programmkode völlig von der Ablaufumgebung des zugrundeliegenden Betriebssystems (meist Linux, aber auch Windows) abkapseln, weil sie alle notwendigen Umgebungsbestandteile selbst enthalten und nur noch auf die im Container abstrahierten Systemcalls des darunterliegenden Betriebssystems angewiesen sind. Container Orchestration-Systeme sind verteilte (Betriebs-)Systeme, die Container nach Bedarf starten und beenden, auf mehrere Rechnerinstanzen verteilen und die Kommunikation zwischen den Container ermöglichen. Ein typischer Container Orchestrator hat folgende Architektur:
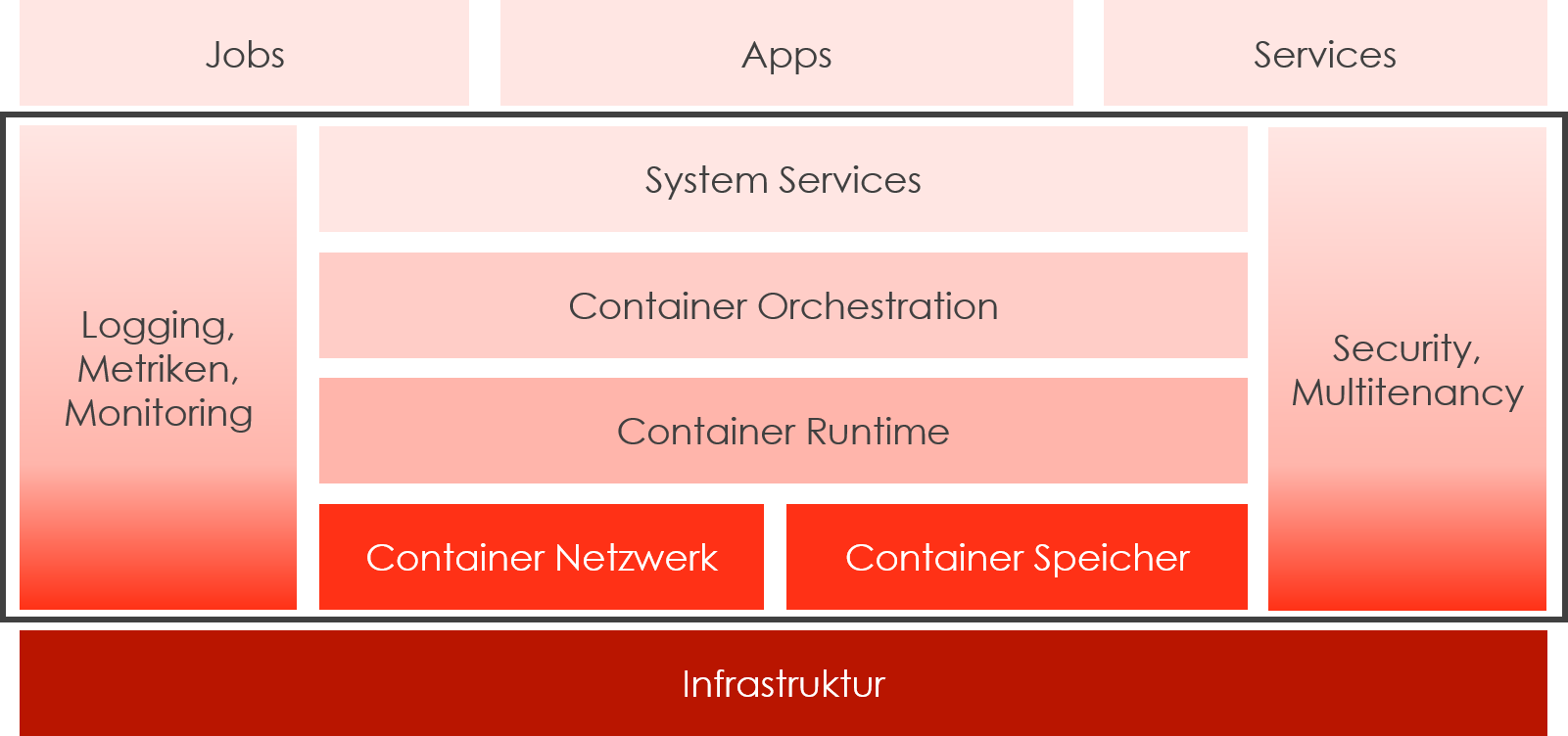
Damit eine Anwendung skalieren kann, verwaltet sich der Container Orchestrator in gewisser Weise selbst, er überwacht die Funktionsfähigkeit der Container, die Auslastung der Computing-Ressourcen, die Netzwerkadressen und -schnittstellen usw. und konfiguriert sich automatisch entsprechend um. Die Cloud-Infrastruktur liefert dafür hochgradig dynamisch Ressourcen wie virtuelle Systeme, Speicher und Netzwerkkanäle. Auch eine Softwareverteilung ist in einem Container Orchestrator nicht mehr notwendig, man teilt dem Orchestrator lediglich mit, dass es eine neue Version eines Containers gibt und er beendet frei werdende Container-Instanzen und startet Container mit der neuen Version nach. Damit sind Container Orchestratoren ideale Plattformen für agile Softwareentwicklung und dem damit verbundenen DevOps-Konzept.
Die derzeit populärste Container Orchestrator-Software ist Kubernetes, eine Open Source-Technologie von Google. Praktisch alle Container-basierten Anwendungen in der Public Cloud wurden in 2017 mit Kubernetes realisiert, so dass AWS und Azure nun sog. Kubernetes Managed Services anbieten, also Services, bei denen der Kunde sich um die Bereitstellung und Wartung der Kubernetes-Umgebung nicht mehr selbst kümmern muss und nur noch die individuelle Kubernetes-Konfiguration für die Anwendung und die auszuführenden Container-Images für die Microservices beistellen muss. Aufgrund dieser Entwicklungen muss man eigentlich ein über das NIST-Modell hinausgehendes Cloud-Plattform-Modell betrachten, welches in etwa so aussehen könnte:

Der Vollständigkeit halber sei hier noch der Begriff Function Plattform erläutert: Neben den Container-Plattformen wird sog. Serverless Computing immer mehr genutzt. Beim Serverless Computing stellt der Nutzer nur noch den Code (Javascript, C# oder F# und mit verschiedenen Skripterstellungsoptionen wie Python, PHP, Bash, Batch und PowerShell) in der Public Cloud bereit und der Cloud-Anbieter kümmert sich um die Ausführung des Codes, wenn ein Auslöser (Trigger), z.B. ein API-Aufruf mittels HTTP-Protokoll oder ein definiertes Ereignis erfolgt. Der Kunde muss dafür keinen Server mehr anmieten oder starten, er bezahlt nur die für die Ausführung des Codes verbrauchte Rechenzeit.
Herausforderungen an das Cloud Management
IT Systems Management
Dynamik, Flüchtigkeit von Ressourcen, Autoscaling: Wie man aus den bisherigen Erläuterungen leicht erkennen kann, kommt die IT-Abteilung mit ihren klassischen Methoden und Tools für das IT Systems Management in einem solchen Umfeld nicht mehr weit, weil sie viel zu statisch für die dynamischen Anwendungsumgebungen in der Cloud sind. Natürlich kann man einen virtuellen Server in der Cloud mit einem Nagios-Agenten überwachen, aber das ist eigentlich nur praktikabel, wenn dieser eine halbwegs überschaubare Lebenszeit hat. In einem „atmenden“ Kubernetes-Cluster, in dem laufend Serverinstanzen gestartet und wieder beendet werden, lässt der damit verbundene Konfigurationsaufwand dies schon gar nicht mehr zu.
Intransparenz, Zugangssperren zu niedrigeren Schichten: Zudem ist es beim typischen Cloud-Service überhaupt nicht mehr möglich, mit eigenen Tools quasi „unter der Haube“ zu überwachen, weil diese Schichten in der Cloud Fabric nicht zugänglich sind. Was will man beim Serverless Computing noch monitoren? Letztlich kommt es lediglich darauf an, dass der Cloud-Provider seine Service Level Agreements bezüglich Verfügbarkeit und Performanz einhält, die Details der Umsetzung sind in seiner Verantwortung.
Failover: Alle führenden Cloud-Anbieter betreiben zahlreiche Rechenzentren (Regions) über den gesamten Globus verteilt, von denen ein jedes in mehrere sog. Availability Zones unterteilt sind. Availability Zones sind physisch und logisch getrennte, aber durch schnelle Leitungen verbundene Bereiche, die einen erweiterten Schutz gegen den Ausfall einzelner RZ-Bereiche bieten. Die Cloud Fabric bietet Möglichkeiten an, Services und Daten in mehreren Availability Zone zu replizieren und bei einem Ausfall den Service in eine andere Zone umzuschalten. Mit den Möglichkeiten der angebotenen Cloud Services (Dynamische DNS) ist es auch möglich, dass bei Ausfall einer Region, der Verkehr in eine andere Region umgeleitet wird. Klassische Monitoring- und Loggingsysteme hätten mit einer derartigen Konstellation große Probleme, die Einrichtung geeigneter Automatismen um mit diesen Szenarien umzugehen, sind äußerst komplex. Die cloud-eigenen Überwachungsmöglichkeiten haben damit keine Probleme.
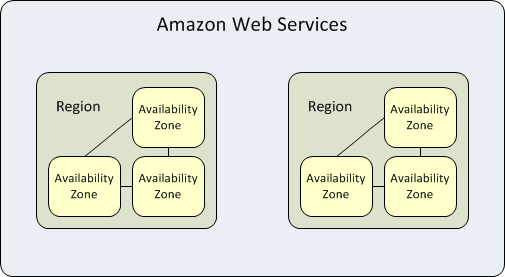
Ungeachtet dessen, will und muss der Cloud-Nutzer Informationen zu Vorgängen in den Cloud-Services und bestimmten Metriken haben, z.B. um Fehler in Anwendungen zu analysieren oder aus Compliance-Gründen alle Änderungen an der Konfiguration eines Cloud Service zu protokollieren. Hier kommen nun Services in Spiel, die der Cloud-Provider selbst anbietet. Sie liefern diese Metriken und Logging-Daten, die benötigt werden, weil sie Teil der Cloud Fabric sind. Die Metriken können mit cloud-eigenen Überwachungsservices verknüpft werden, die Aktionen auslösen, wenn bestimmte Ereignisse eintreten bzw. Schwellwerte erreicht werden. Logging-Daten können in Speicherdiensten archiviert werden oder in Analyse-Systeme geleitet werden, wo sie auswertet werden oder auch Alarme bei Auftreten bestimmter Muster ausgelöst werden. Zudem werden Visualisierungen in Form von Dashboards angeboten.
IT Service Management und Softwareentwicklung
DevOps: Dieses neue Konzept ist nicht nur technisch eine Herausforderung sondern auch prozessual, es fordert das klassische Verständnis der IT Service Management-Prozesse heraus. Weil die Konfiguration der Ablaufumgebung, z.B. eines Kubernetes-Clusters, ein inhärenter Teil der Anwendung ist und in Zukunft weitgehend von der Softwareentwicklung bestimmt werden muss, geht die klassische Trennung zwischen Entwicklung und Betrieb verloren, was auch Auswirkungen auf die Verantwortung und Behandlung Incident Management hat. Das weitgehende Wegfallen definierter Softwarereleases wie in der Vergangenheit und ein individuelles Deployment von einzelnen Microservices jeweils nach agilen Sprints erfordert ein Umdenken im Release und Deployment Management und eine Fokussierung auf Ergebnisse und weniger auf bestimmte Methoden.
Configuration Management: Eine lückenlose Repräsentation aller aktiven IT-Ressourcen in einer CMDB ist mit der Dynamik der Cloud nicht mehr vereinbar, es muss definiert werden, bis zu welcher Ebene Cloud-Ressourcen als Configuration Items (CI) geführt werden sollen, z.B. Cluster und Services, aber keine Kubernetes-Nodes oder -Pods.
Event Management: Nicht vorhandene CIs und Abhängigkeiten in der CMDB können ein Problem für die Tools und Menschen im Operating darstellen. Zudem sind die Bezeichnungen von IT-Ressourcen in der Cloud ebenfalls dynamisch und daher kryptisch, der Zusammenhang von Ressourcen mit Services lässt sich nicht mehr einfach erkennen. Abhilfe können hier nur Tools schaffen, die speziell für den Einsatz in solchen dynamischen Umgebungen geschaffen sind und die aktuelle Konfiguration und ihren Zustand in Realzeit ermitteln und darstellen.
Capacity und Availability Management: Durch die mit dem Cloud-Provider vereinbarten Service Level Agreements (SLA) wird das Availability Management zu einer Aufgabe des Provider Managements, in dem lediglich die Leistung des Cloud-Providers überwacht werden muss, einen Einfluss auf die Art und Weise der Erbringung der Service-Leistung hat der Kunde ohnehin nicht mehr und will sie auch nicht mehr haben. Fiktiv sind die verfügbaren Ressourcen in dem Clouds unbegrenzt und faktisch nur durch das Budget des Kunden limitiert. Capacity Management wandelt sich also von der Planung und Überwachung der verfügbaren Ressourcen auf die Überwachung und Optimierung des eingesetzten Budgets, d.h. kann man die benötigten Ressourcen durch die Auswahl von bestimmten Services und Tarifen günstiger einkaufen.
Service Level und Continuity Management: Diese beiden Disziplinen sind in Zukunft viel weniger durch infrastrukturelle Aspekte bestimmte, weil die Kapazitäten, Fähigkeiten und Lokationen ja vorhanden sind und lediglich angemietet werden müssen. Die Verantwortung verlagert sich nun auf die Cloud-Architekten, die Anwendungsarchitekturen designen müssen, die die Möglichkeiten der Cloud auch nutzen.
Lesen Sie weiter
Im zweiten Teil des Artikels befassen wir uns mit der Realisierung von Monitoring und Logging in der Cloud und ziehen ein Fazit aus beiden Teilen.