Praktisch alle mittleren und großen Unternehmen haben sich inzwischen eine Cloud-Strategie verschrieben. Teil 2 des Artikels zum Cloud Management mit Beispielen zur Realisierung.
Fahrplan
Dies ist Teil 2 einer Serie von Blog-Beiträgen zum Thema Management in der Cloud. Wenn Sie es noch nicht getan haben, lesen Sie auch Teil 1.
Realisierung
Es ist deutlich geworden, dass die bisherige Tool-Ausstattung der IT-Abteilungen den Herausforderungen der Cloud nicht gewachsen ist und Defizite aufweist. Die einzige Lösung ist ein konsequenter Einsatz der cloud-eigenen Management-Services. Zum Glück müssen die Cloud-Provider mit diesen Tools ihren eigenen Service managen und wissen daher sehr genau, was benötigt wird, deshalb sind die Angebote auch sehr funktional und überzeugend.
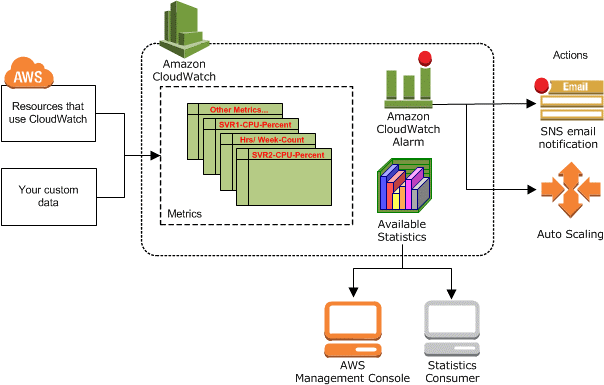
Beginnen wir mit dem Marktführer AWS: AWS bietet mit CloudWatch einen Service der Zugriff auf die Metriken (KPIs) in praktisch allen bei AWS verfügbaren Cloud-Services bietet. Kombiniert mit einem Regelsystem lassen sich automatische Reaktionen beim Eintritt vordefinierter Ereignisse (z.B. Schwellwerte) auslösen, damit wird z.B. das Autoscaling in AWS EC2 gesteuert. Darüberhinaus lassen sich andere bei AWS verfügbare Services als Bausteine sehr flexibel miteinander kombinieren (z.B. Logging, Speicherung, Archivierung, Analytics, Message Service) und so können mächtige Funktionsketten zusammengestellt werden, die alle Anforderungen bzgl. Überwachung, Logmanagement und Alarmierung erfüllen.
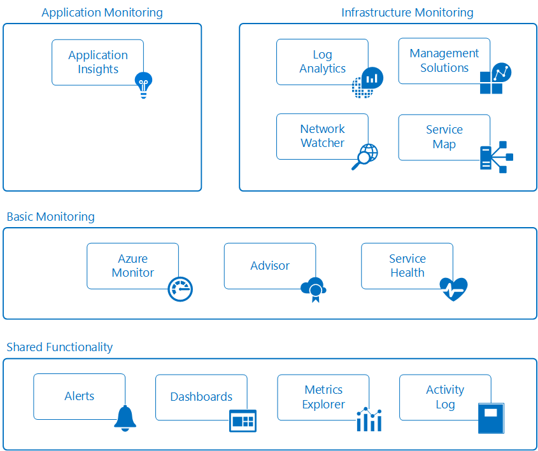
Microsoft setzt in Azure weitgehend auf eine Adaption seiner Systems Management-Produkte und bietet ebenfalls ein umfassendes Portfolio an Services an:
Eine schwere Herausforderung stellt das zukünftige Configurations Management dar, weil – wie bereits erwähnt – weil die Führung einer CMDB in der gewohnten Form bei der Dynamik der Ressourcen in der Cloud nicht zielführend ist. Zwar bieten alle Clouds Möglichkeiten an, einen aktuellen Abzug der aktiven Ressourcen zu erstellen, aber welchen Nutzen hat dieser – ohne Beziehungen der Ressourcen untereinander und vor allem ohne vom Operator einfach zu interpretierende Ressourcennamen?
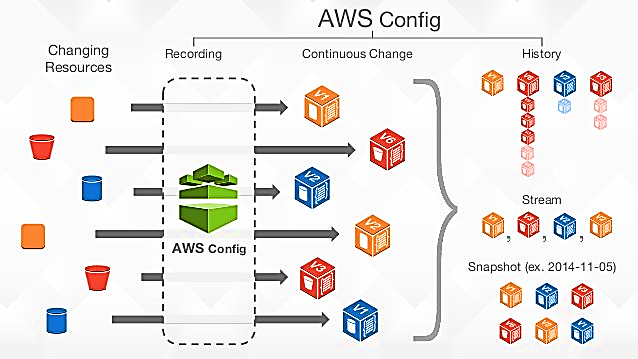
AWS bietet mit AWS Config einen Service an, der zumindest eine Anforderung des Confguration Managements erfüllt, die Führung einer revisionssicheren Historie aller jemals aktiven Ressourcen im Sinne auch von Configuration Baselines:
Als Lösung bietet sich an, sich in der CMDB auf die eher statischen Elemente der Anwendungsarchitekturen zu konzentrieren, so z.B. Architekturbausteine wie Cluster, die darauf zur Verfügung gestellten Services und andere in diesem Zusammenhang genutzte Services wie Datenbanken, Load Balancer, Schnittstellen als Cis zu modellieren. Diese Elemente sind aus der Architektur einer Anwendung vorgegeben und ändern sich nicht häufig.
Aber wo sollen diese Architekturdefinitionen als Grundlage für die CMDB-Inhalte denn herkommen? Interessanterweise bietet AWS mit CloudFormation ein Tool an, mit dem Musterarchitekturen für AWS-Services spezifiziert werden können. Daraus können AWS CLI-Befehlsskripte generiert werden, um selbst komplizierte Service-Aggregate auf Knopfdruck zu instanziieren. Damit würden maschinenlesbare Beschreibungen von Architekturen enstehen, die in CMDB-Informationen überführt werden können. Voraussetzung ist allerdings, dass die Cloud-Architekten diese Methode auch weitgehend konsequent für alle Cloud-Anwendungen nutzen.
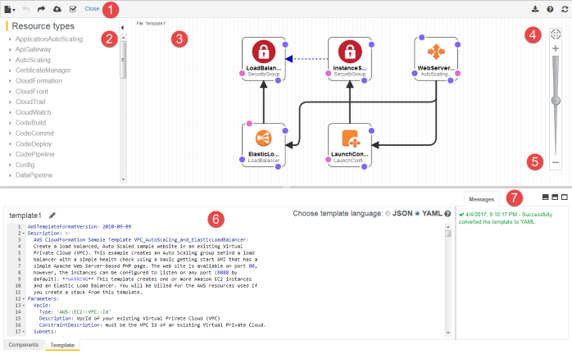
Ergänzungen mit zusätzlichen Tools
Trotz der Empfehlung in erster Linie die cloud-eigenen Überwachungstools zu verwenden, kann es sinnvoll sein, Tools von Drittanbieter in der Cloud einzusetzen, z.B. weil die cloud-eigenen Services (noch) nicht die benötigte Funktionalität bieten. Dies ist derzeit im Bereich Application Performance Management (APM) und dem damit verbundenen Trouble Shooting der Fall.
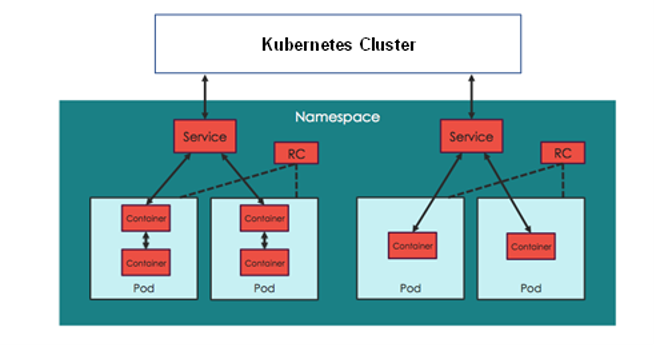
AWS bietet zwar mit Xray einen Tracing-Service an, ebenso Microsoft mit Applications Insight in Azure, aber es es gibt leistungsfähigere Lösungsansätze und Tools ausserhalb, insbesondere mit der Kombination von APM und Realtime Configuration Discovery in Kubernetes Clustern. Zwei Produkte, die sowohl als SaaS- und On-Premise-Lösung verfügbar sind, fallen hier besonders ins Auge.
Sysdig ist ein Anbieter aus den USA, der ein sehr ansprechendes Produkt für das Performance Management von Container-Umgebungen entwickelt hat. Mittels einer minimalen Linux-Kernel-Erweiterung ist es in der Lage, alle Systemcalls der darauf ablaufenden Programme (und Container) zu tracen und in Kombinationen mit einem Configuration Discovery im Cluster sich ein Lagebild über den Zustand und die Laufzeiten von Transaktionen in den Services auf dem Cluster zu verschaffen.
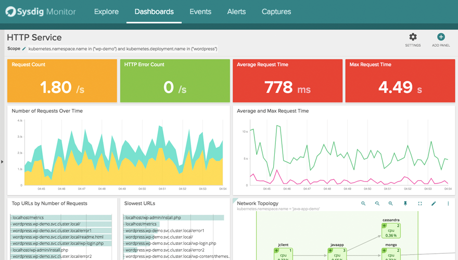
Das Produkt Instana, von einem deutschen Hersteller, ist ein eher typisches APM-Tool, das sehr präzise per Tracing die Laufzeiten der Transaktionen in und zwischen den Containern aufzeigt. Auf dieses Tool kann, wie Sysdig, Alarme an ein Event Management auslösen.
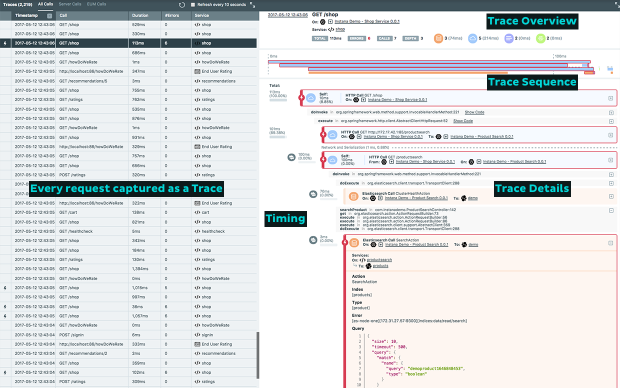
Integration mit dem unternehmenseigenen Leitstand und Service Management
Nachdem wir nun die Instrumentierung in der Cloud gelöst haben, müssen wir uns mit der Integration in der Alarmierung aus der Cloud in den unternehmenseigenen Leitstand und das Service Management-Tool widmen. Vorausgeschickt sei, dass die Abhandlung hier eine sehr vereinfachte und sicher nicht umfassende ist, dazu sind die Gegebenheiten in den Unternehmen viel zu unterschiedlich.
Aus der Cloud werden Alarme verschickt, die Linqua franca der Cloud sind REST-Calls mit JSON-Playload, sog. Webhooks. Einige Event Management-Systeme in den unternehmenseigenen Leitständen können dieses Protokoll direkt verstehen, ältere Systeme eher nicht. Für diese älteren Systeme kann ein Webhook-Gateway etabliert werden, der die Webhook-Calls aus Cloud entgegen nimmt und in kompatible Protokolle oder Aufrufe von CLI-Kommandos umwandelt. Eine vereinfachte Architektur stellt sich folgendermassen dar:
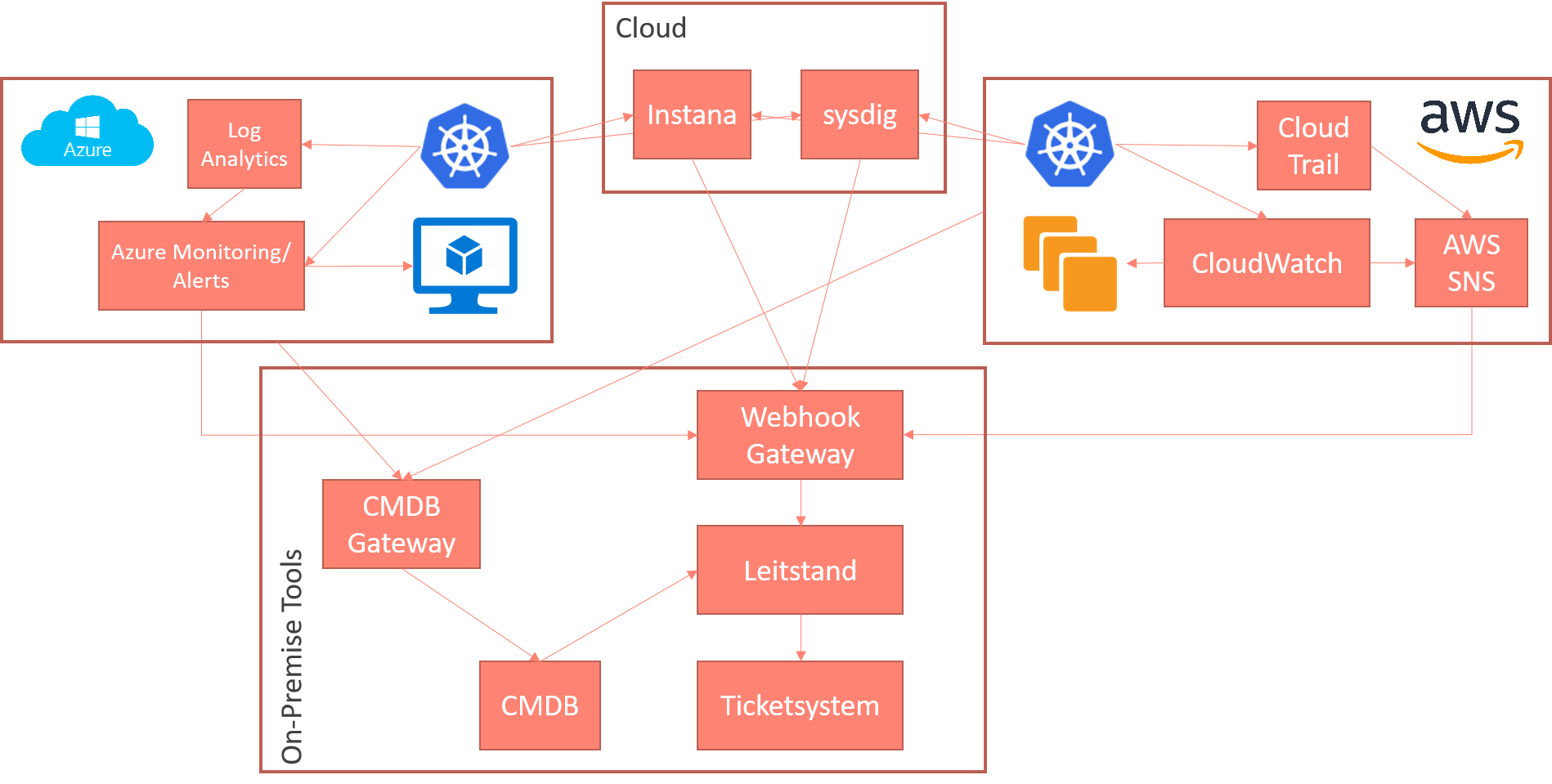
Im Schaubild nicht ausgewiesen sind die Zugriffsmöglichkeiten des Operating-Personals auf Managementsysteme in der Cloud und deren Portale und Dashboards.
Fazit zum Cloud Management
Abschließend können folgende Schlussfolgerungen gezogen und Empfehlungen ausgesprochen werden:
- Die Public Cloud operiert mit wesentlich anderen Konzepten und bietet andere Möglicheiten wie das klassische eigene Rechenzentrum, eine äquivalente Private Cloud kann nur unter Zuhilfenahme von Technologien führender Cloud-Anbieter (z.B. Microsoft Azure Stack) im eigenen Rechenzentrum etabliert werden
- Zukünftige Anwendungsarchitekturen in Cloud-Umgebungen unterscheiden sich deutlich von den klassischen Anwendungsarchitekturen, sie nutzen die Agilität und Skalierbarkeit der Cloud. Die dabei eingesetzten Softwareplattformen sind andere wie früher.
- Die Services der Cloud-Plattformen sind in der Cloud Fabric angesiedelt und von außen für Überwachungstools nicht erreichbar. Nur die Cloud Fabric hat alle aktuellen Informationen über die Ressourcen eines Kunden und deren Zustand. Deshalb sollten die cloud-eigenen Überwachungs- und Alarmierungsmöglichkeiten genutzt werden.
- Die klassischen on-premise Systems Management-Tools sind der Dynamik von Cloud-Umgebungen nicht gewachsen, ihr Einsatz in der Cloud macht deshalb keinen Sinn.
- Wo die cloud-eigenen Überwachungsfunktionen noch nicht ausreichend sind, kann mit Management-Produkten ergänzt werden, die speziell auf die Anforderungen der Cloud und die dort eingesetzten Anwendungsarchitekturen vorbereitet sind.
- Die Charakteristiken der Cloud und ihre Dynamik werden Auswirkungen auf das bisherige Verständnis von Prozessen und Rollen (Service Management, Softwareentwicklung) in der IT haben, die Unternehmen sollten sich darauf vorbereiten, dafür neue Vorgaben erarbeiten und organisatorische Anpassungen vornehmen.
Zum Schluss gilt es noch die Frage zu beantworten, wie übertragbar diese Schlussfolgerungen und Empfehlungen auf andere Unternehmen und Cloud-Anbieter sind, z.B. bzgl. der Cloud-Strategie und dem Cloud-Provider:
- Jedes Unternehmen wird – abhängig von der Branche, seinen Unternehmenszielen und seinen Unternehmensanwendungen – seine ganz eigene Cloud-Strategie entwickeln müssen, dafür mit welchen Anwendungen sie in die Cloud gehen und was das Betriebsmodell sein soll. Das hier vorgestellte Szenario ist jedoch sicher exemplarisch für große Unternehmen.
- AWS gibt als Marktführer vor, was eine Public Cloud leisten kann. Unsere Erfahrung ist, dass die anderen führenden Anbieter bestrebt sind, bei den Service-Angeboten weitgehend Parität mit AWS herzustellen, die Servicekataloge sind funktional in weiten Teilen deckungsgleich. Trotzdem hat jeder Cloud-Provider seine spezifischen Alleinstellungsmerkmale: Microsoft ist mit Office365 ein SaaS-Anbieter für Desktop-nahe Dienste, IBM schneidet seinen Servicekatalog auf seine Bestandskunden in den Konzernen zu und AWS bietet die Services für weltweit bereitgestellte mega-skalierbare Angebote à la Facebook, Netflix usw. Im Computing-Angebot, dort wo die Grundlagen der Cloud ruhen, müssen sie alle im Wesentlichen die gleichen Services zur Verfügung halten.